Abstract
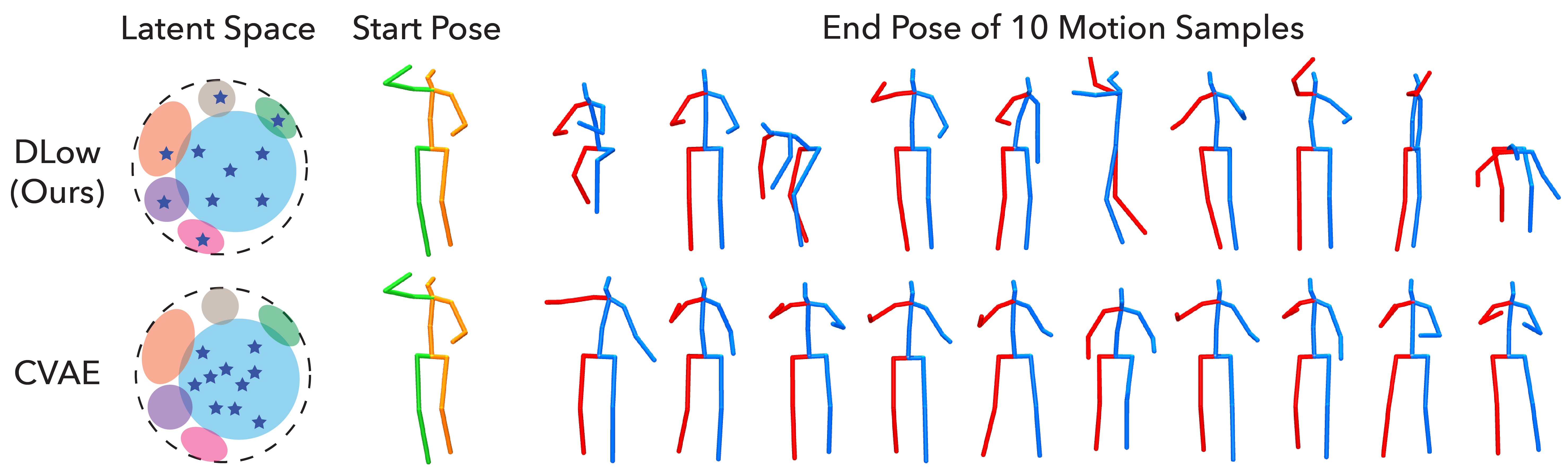
Deep generative models are often used for human motion prediction as they are able to model multi-modal data distributions and characterize diverse human behavior. While much care has been taken into designing and learning deep generative models, how to efficiently produce diverse samples from a deep generative model after it has been trained is still an under-explored problem. To obtain samples from a pretrained generative model, most existing generative human motion prediction methods draw a set of independent Gaussian latent codes and convert them to motion samples. Clearly, this random sampling strategy is not guaranteed to produce diverse samples for two reasons: (1) The independent sampling cannot force the samples to be diverse; (2) The sampling is based solely on likelihood which may only produce samples that correspond to the major modes of the data distribution. To address these problems, we propose a novel sampling method, Diversifying Latent Flows (DLow), to produce a diverse set of samples from a pretrained deep generative model. Unlike random (independent) sampling, the proposed DLow sampling method samples a single random variable and then maps it with a set of learnable mapping functions to a set of correlated latent codes. The correlated latent codes are then decoded into a set of correlated samples. During training, DLow uses a diversity-promoting prior over samples as an objective to optimize the latent mappings to improve sample diversity. The design of the prior is highly flexible and can be customized to generate diverse motions with common features (e.g., similar leg motion but diverse upper-body motion). Our experiments demonstrate that DLow outperforms state-of-the-art baseline methods in terms of sample diversity and accuracy.
1min Summary
10min Talk
Results Video
Citation
@inproceedings{yuan2020dlow,
title={Dlow: Diversifying latent flows for diverse human motion prediction},
author={Yuan, Ye and Kitani, Kris},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2020}
}
|
Template adapted from GLAMR. |